Funciones ( SUBPROGRAMAS O SUBALGORITMOS)
1. INTRODUCCIÓN A LOS SUBPROGRAMAS
O SUBALGORITMOS:
La programación modular es una
de las técnicas fundamentales de la programación. Se apoya en el diseño
descendente y en la filosofía de “divide y vencerás”, es decir se trata de
dividir el problema dado, en problemas más simples en que cada uno de los cuales
lo implementaremos en un módulo independiente. A cada uno de estos módulos es a
lo que llamamos subalgoritmos o subprogramas.
Hay dos tipos fundamentales de
subprogramas: Funciones y procedimientos.
2. FUNCIONES:
Desde el punto de vista
matemático, una función es una operación que toma uno o varios operando, y
devuelve un resultado. Y desde el punto de vista algorítmico, es un subprograma
que toma uno o varios parámetros como entrada y devuelve a la salida un único resultado.
Pascal: En
las funciones se puede devolver más de un único resultado mediante parámetros.
C: Se devuelve todo por
parámetros.
Este único resultado irá
asociado al nombre de la función. Hay dos tipos de funciones:
Internas: Son las que vienen
definidas por defecto en el lenguaje.
Externas:
Las define el usuario y les da un nombre o identificador.
Para llamar a una función se da
su nombre, y entre paréntesis van los argumentos o parámetros que se quieren
pasar.
Declaración
de una función:
La estructura de una función es
semejante a la de cualquier subprograma. Tendrá una cabecera (con el nombre y
los parámetros) y un cuerpo(con la declaración de los parámetros de la función
y las instrucciones).
Sintaxis:
Funcion <nombre_funcion>
(n_parametro: tipo, n_parametro: tipo): tipo funcion
Var <variables locales
funcion>
Inicio
<acciones>
retorno <valor>
fin <nombre_funcion>
La lista de parámetros es la
información que se le tiene que pasar a la función. Los parámetros luego dentro
de la función los podemos utilizar igual que si fueran variables locales
definidas en la función y para cada parámetro hay que poner su nombre y tipo.
La función puede ser llamada desde el programa
principal o desde cualquier otro subprograma.
Pasos
para hacer la llamada a una función:
Al hacer la llamada y ceder el control a la
función, se asocia (asigna el valor) de cada parámetro real a cada parámetro
formal asociado, siempre por orden de aparición y de izquierda a derecha, por
lo que siempre que no coincidan los tipos y el número de parámetros formales y
reales, se produce un error.
Otra
forma de especificar el retorno de una función:
Se le asigna el valor devuelto
al nombre de la función.
Función valor
Ejemplo de función:
Una función que calcule la
mitad del valor que le paso parámetro. Suponemos que es un valor entero.
Funcion mitad (n: entero): real
Var m: real
Inicio
M n/2
Retorno m
Fin mitad
Algoritmo calc_mitad
Var num: entero
Inicio
Escribir “Introduce un número para hallar su
mitad”
Leer num
Escribir “La mitad de “num” es “mitad(num)
Fin
3. PROCEDIMIENTOS:
El inconveniente de una función
es que solo puede devolver un único valor, por lo que sí nos interesa devolver
0 o N valores, aunque puedo usarlo para devolver un solo valor, debo usar un
procedimiento.
Un procedimiento es un
subprograma o un subalgoritmo que ejecuta una determinada tarea, pero que tras
ejecutar esa tarea no tienen ningún valor asociado a su nombre como en las
funciones, sino que si devuelve información, lo hace a través de parámetros.
Al llamar a un procedimiento,
se le cede el control, comienza a ejecutarse y cuando termina devuelve el
control a la siguiente instrucción a la de llamada.
Diferencias
entre funciones y procedimientos:
Una función devuelve un único valor y un
procedimiento puede devolver 0,1 o N.
Ninguno de los resultados devueltos por el
procedimiento se asocian a su nombre como ocurría con la función.
Mientras que la llamada a una función forma
siempre parte de una expresión, la llamada a un procedimiento es una
instrucción que por sí sola no necesita instrucciones.
Esta llamada consiste en el
nombre del procedimiento y va entre paréntesis van los parámetros que se le
pasan. En algunos lenguajes (como el C), se pone delante la palabra Llamar a
(Call) procedimiento (parámetro).
Sintaxis:
Procedimiento
<nombre_proc> (<tipo_paso_par> <nombre_par>: tipo_par,...)
Var <variables locales>:
tipo
Inicio
<sentencias>
fin <nombre_proc>
La cabecera va a estar formada
por el nombre del procedimiento que será un identificador y que debe de ser
significativo, y luego entre paréntesis los parámetros o la información que se
le pasa al procedimiento. Para cada parámetro hay que indicar el tipo de paso
de parámetro. Hay dos tipos fundamentales de paso de parámetros, por valor y
por referencia, si no ponemos tipo de paso de parámetros, se toma el tipo de
paso de parámetros por valor.
En el cuerpo del procedimiento
donde van las sentencias ya no habrá ninguna de tipo <retorno valor>,
ahora bien, si el procedimiento devuelve resultados a través de sus parámetros,
cosa que solo podrá hacer a través de los parámetros que se pasan por
referencia, tendrán que existir sentencias de asignación de valores a estos
parámetros pasados por referencia, a través de los cuales se van a devolver los
resultados.
Como se llama a un
procedimiento:
[llamar a (Call)] nombre_proc
(par_reales)
Pasos
para hacer la llamada a un procedimiento:
Se cede el control al procedimiento al que se
llama y lo primero que se hace al cederle el control es sustituir cada
parámetro formal de la definición por el parámetro actual o real de la llamada
asociado a él. Esta asociación entre parámetros formales y reales se hace de
izquierda a derecha por orden de colocación y para que se pueda producir esta
asociación tienen que existir el mismo número de parámetros formales que reales,
y además el tipo tiene que coincidir con el del parámetro formal asociado, sino
se cumple alguna de estas condiciones hay un error.
Si la asociación ha sido correcta comienzan a
ejecutarse las instrucciones del procedimiento hasta llegar a la última instrucción.
Al llegar a la instrucción se vuelven a asociar los parámetros formales que
devuelven los resultados a los parámetros formales asociados en la llamada, es
decir, de esta manera algunos de los parámetros reales de la llamada ya
contendrán los resultados del procedimiento.
Finalmente se cede el control a la siguiente
instrucción a la que se hace la llamada, pero teniendo en cuenta que en esta
instrucción y en las siguientes puedo usar ya los parámetros reales en los que
se devolvieron los resultados del procedimiento para trabajar con ellos.
Procedimiento mitad
(num:entero,ent-sal M:real)
Inicio
M num/2
Fin mitad
Algoritmo calc_mitad
Var
N: entero
Mit: real
Inicio
Escribir “Introduce un número”
Leer n
Mitad (n,mit)
Escribir “La mitad es”mit
fin
4. COMUNICACIÓN ENTRE SUBPROGRAMAS: PASO DE
PARÁMETROS.
La mejor forma para llevar a
cabo la comunicación ente subprogramas, es el paso de parámetros. Trataremos de
evitar siempre que sea posible el uso de variables globales.
Cuando llamamos a una función o
procedimiento, le pasamos a través de los parámetros la información que
necesita, y en el caso de un procedimiento también devolvemos a través de sus
parámetros los resultados. Para ello definiremos el tipo del parámetro a
principio del subprograma, que es lo que conocemos como parámetros formales, y
al hacer la llamada pasamos la información a través de los parámetros reales.
¿Cómo se efectúa la
correspondencia entre parámetros formales y reales?:
Existen 2 métodos:
Correspondencia posicional: En este caso se
emparejan los parámetros formales y reales por la posición que ocupan (orden de
declaración) y de izquierda a derecha. Para que se pueda realizar esta
asociación, tiene que haber el mismo número de parámetros formales y reales, y
con el mismo tipo.
F (x:entero,y:real)
Var a:real
F (3,A)
Correspondencia por nombre implícito: Ahora
en la llamada al subprograma se pone explícitamente a que parámetro formal
corresponde cada real.
Ahora en la llamada ponemos el
nombre del parámetro formal, separado por dos puntos (:) y el nombre del
parámetro real que le pasamos, con lo cual ya no importa la posición en la que
coloquemos la información.
F (x:3,y:A)
F (y:A,x:3)
Un lenguaje que permite esto es
ADA.
Usaremos siempre el primer
método (posicional).
Paso de parámetros:
Del modo de paso de parámetros
va a depender el resultado que se obtenga.
1. Tipos de parámetros: Según se usen para meter datos o para
obtener resultados.
Existen 3 tipos:
De entrada: Son parámetros que solo aportan
información de entrada al subprogama en el que pertenecen como parámetros. Aporta
el valor que tienen como entrada al subprograma. En el caso de una función,
todos sus parámetros son de este tipo.
Como solo sirven como entrada,
solo pueden ser leídos, pero no modificados, y aunque se modificasen dentro de
un subprograma, fuera no va a tener efecto esa modificación.
De salida: Se usan solo y exclusivamente para
devolver resultados a través de ellos. Su valor al hacer la llamada al
subprograma no nos importa, sino que ese valor solo va a tener importancia
cuando termina la ejecución del programa. Un parámetro de este tipo
teóricamente nunca se puede leer, solo se va actualizar.
De entrada y salida: El valor del parámetro
tiene importancia tanto a la entrada como a la salida del subprograma, nos
aporta información cuando llamamos al subprograma y por otra parte devolvemos a
través de él resultados cuando terminamos el subprograma, en este caso, tiene
sentido tanto leer como actualizar el parámetro.
Solo ADA es un lenguaje que va
a soportar los 3 tipos de paso de parámetro. Se ponen como In, Out, In-Out.
El resto de los lenguajes solo
permiten dos tipos de parámetros, de entrada (solo para leer datos) y de
entrada-salida (para devolver resultados, aunque también se puede usar para
leer datos).
2. Métodos de paso de parámetros:
Paso de parámetros por copia:
Por valor.
Por resultado.
Por valor-resultado.
Paso de parámetros por
referencia.
Paso de parámetros por nombre o
nominal.
Paso de parámetros por copia:
La característica fundamental
de este método de paso de parámetros es que el parámetro formal siempre se
considera que tiene asociada una dirección de memoria en la que está almacenado
y que por tanto se comporta igual que una variable local del subprograma en que
aparece.
En este método lo que importa
es el valor del parámetro actual.
Por valor: Nos interesa el valor del
parámetro actual a la entrada, para ello este valor se copia en la dirección de
memoria del parámetro formal asociado. En este caso el parámetro real puede se
una constante, expresión o variable, y nunca se va a usar para devolver
resultado a través de él, por esa razón precisamente puede ser una constante o
una expresión, porque al no devolver resultados a través de él no necesita tomar
ninguna zona de memoria en la que este almacenado, es más, incluso si el
parámetro actual fuera una variable y la modificásemos dentro del subprograma
(algo que no deberíamos hacer), fuera del subprograma no tendría ninguna
repercusión esta modificación, es decir, esa variable serviría valiendo lo
mismo en el programa desde el que se hace la llamada después y antes de
hacerla.
El funcionamiento sería el
siguiente:
Al hacer la llamada al
subprograma se evalúa el valor del parámetro real, y ese es el que se asocia,
es decir, el que se guarda o asigna al parámetro formal asociado.
Comenzamos a ejecutar el
subprograma y si por casualidad se produce algún cambio en el parámetro formal,
el parámetro actual no se verá afectado, es decir, su valor seguirá siendo el
mismo en el subprograma desde donde se llama que antes de hacer la llamada al
subprograma.
Algoritmo Ej.
Var A:entero 3 3 6
Inicio A del PP X de P
A 3
P (A)
Escribir A
Fin
Procedimiento P(x:entero)
Inicio
X x*2
Escribir x
Fin p
El valor de A sería 3 y el de X
sería 6.
Por valor-resultado: En el
valor-resultado nos interesa el valor del parámetro actual tanto a la entrada
como a la salida de la ejecución del subprograma.
Esto quiere decir que se cambia
el valor del parámetro formal cambiará también el valor de su parámetro real
asociado, cosa que no ocurría antes, y esto supone por tanto que ahora el
parámetro real tiene que tener asociada obligatoriamente una dirección de
memoria, por lo que siempre tendrá que ser una variable (no una constante ni
una expresión).
El proceso sería el siguiente:
- Al hacer la llamada al
subprograma se evalúa el parámetro real y su valor se copia en el parámetro
formal asociado y al terminar la ejecución el valor del parámetro formal se
vuelve a copiar en el parámetro real asociado.
Algoritmo Ej.
Var A:entero Se copia
Inicio
A 3
P (A) 3 6 3 6
Escribir A P.Real P.Formal
Fin
Procedimiento P(x:entero)
Inicio Se devuelve
X x*2
Escribir x
Fin p
El valor de la A y la X sería
6.
Por resultado: Nos interesa el valor del
parámetro real solamente a la salida o fin de la ejecución del subprograma en
que aparece. Esto significa que al hacer la llamada no se copia el valor del
parámetro real en el parámetro formal asociado, sin embargo a la salida se copia
el valor del parámetro formal en la dirección del parámetro real asociado, esto
significa por tanto, que el parámetro real tiene que tener asociada una
expresión que tiene que ser una variable (no puede ser una constante o una
expresión).
Algoritmo
Var A:entero
Inicio
A 3 P.Real P.Formal
P (A)
Escribir A
Fin
Procedimiento P(x:entero) Se copia a la
salida
Inicio
X 1
X x*2
Escribir x
Fin p
El valor de A y de X es 2.
En la práctica la mayor parte
de los lenguajes dentro del tipo de paso de parámetro por copia solo van a
soportar el tipo de paso de parámetro por valor, que se usará cuando un
parámetro solo lo quiero utilizar como entrada de información al subprograma,
pero no para devolver resultados a través de él.
Los otros dos tipos de paso de
parámetros por copia (por valor y por valor-resultado), no se implementan
normalmente porque los efectos son prácticamente iguales que el paso de
parámetros por referencia, es decir, cuando quiero usar un parámetro no solo
para pasar información a través de él sino también para devolver resultados o
si lo voy a usar sólo para devolver resultados, utilizaré el paso de parámetros
por referencia que vamos a ver a continuación.
Para simbolizar que el tipo de
paso de parámetros es por valor, en la definición del subprograma no pongo
ningún tipo de paso de parámetros para ese parámetro, es decir, no poner ningún
tipo significa que por defecto el tipo de paso de parámetros es por valor.
En el caso de las funciones
como solamente pueden recibir información de entrada pero nunca pueden devolver
información por sus parámetros ya que lo devuelven a través de la sentencia
retorno y asociado a su nombre.
El tipo de paso de sus
parámetros va a ser siempre por valor.
Paso de parámetros por
referencia:
Ahora la característica
principal de este tipo de paso de parámetros es que el parámetro formal va a
tener también asignada una dirección de memoria en la que se almacena, pero en
esa dirección NO SE GUARDA SU VALOR, sino que se almacena la
dirección de su parámetro real asociado, es decir, el parámetro formal apunta
al parámetro real que tiene asociado y cualquier modificación que se efectúe
sobre el parámetro formal tendrá una repercusión directa en el parámetro real
asociado ya que lo que modificará será el valor almacenado en la dirección que
indica el parámetro formal que es la de su parámetro formal asociado.
El proceso será por tanto el
siguiente:
Al hacer la llamada al
procedimiento en el parámetro formal que se pasa por referencia, se va a
guardar la dirección del parámetro real asociado para que apunte a él.
Durante la ejecución cualquier
referencia al parámetro formal se hará accediendo a la dirección apuntada por
dicho parámetro, es decir, accediendo directamente al parámetro real asociado,
por lo que cualquier cambio en el parámetro formal afectará directamente al
parámetro real asociado. De esta manera habremos pasado el resultado.
Para indicar que el tipo de
paso de parámetro es por referencia, vamos a utilizar la palabra clave ent-sal
precediendo al parámetro que se pasa por referencia.
A estos parámetros también se
les llama parámetros variables (porque su valor varía), por eso en Pascal se
usa la palabra clave Var para indicarlo.
En otros lenguajes como C, se
usan como parámetros punteros para indicar que son direcciones.
Algoritmo EJ
Var A apunta
Inicio
A 3
P1(A) 3 dirección A
Escribir (A)
Fin A del PP X del P1
Procedimiento P1(ent-sal x:entero)
Inicio
X x*2
Fin P1
Por valor el parámetro actual
no cambia de valor.
Por referencia el parámetro
actual puede cambiar.
Paso de parámetros por nombre:
En este caso, el parámetro
formal se sustituye literalmente por el parámetro actual asociado. Esta
sustitución literal del parámetro formal por el parámetro actual no se produce
hasta que no se usa el parámetro formal.
La ventaja es que si no usamos
en ningún momento el parámetro formal dentro del subprograma llamado (cosa poco
probable), no se tendrá que hacer ningún tipo de substitución.
Pero el gran inconveniente es
que si se usa el parámetro formal, hay que ir a buscar en ese momento la
expresión del parámetro real asociado.
El paso de parámetro por nombre
es lo que se parece más a la substitución de parámetros en una función
matemática.
F (x)= x+2
F (a+1) = a+1*2
F (x)= x+2
F (a+1)= a +1 2 <> (a+1)*2
Algoritmo EJ
Var A: entero
Inicio
A 3
P1(A+1)
Escribir (A)
Fin
Procedimiento P1(ent-sal x: entero)
Inicio
X x*2
Fin P1
Al final solo vamos a usar 2
tipos de paso de parámetros, que son los que usan casi todos los lenguajes: Por
valor y por referencia.
Por valor: Solo lo usamos
cuando un parámetro solo sirve para información de entrada, no devolvemos nada
con él. Por eso este paso puede ser una constante, variable o expresión. Para
simbolizarlo en la declaración de variables no ponemos nada.
Por referencia: Lo usamos
cuando un parámetro lo usamos como entrada de información y como salida o solo
como salida. Por esta razón ahora sí que se va a variar el parámetro formal y
por lo tanto no podemos usar constantes ni expresiones, solo variables. Lo
simbolizamos con la palabra ent-sal.
5. FUNCIONES Y PROCEDIMIENTOS COMO
PARÁMETROS:
En la mayor parte de los
lenguajes se permite también que una función o procedimiento pueda ser pasado
como parámetro de otro subprograma. En este caso, es decir, cuando el parámetro
formal es de tipo función o procedimiento, pasaremos como parámetro real funciones
o procedimientos que tengan la misma definición que el que hemos puesto como
parámetro formal, y en nuestro caso para indicar que se pasa como parámetro
real una función o procedimiento, basta con poner su nombre.
Desde el subprograma al que se
pasa como parámetro esa función o procedimiento podemos llamar en cualquier
momento a esa función pasada como parámetro que en cada momento podrá ser una
distinta dependiendo del parámetro formal asociado.
Funcion <nombre_f>
(par:tipo;funcion <n_f>(x:entero,y:carácter):entero
Prodedimiento <nombre_f>
procedimiento (x:tipo,...);...
Algoritmo EJ
Var v1,v2: entero
Inicio
V1 1
V2 2
P(v1,f1,v2)
P(v1,f2,v2)
Fin
Procedimiento
P(x:entero;funcion F(A:entero;B:carácter):entero;ent-sal y:entero)
Inicio
X 2
Y F(x,'a')
Fin P
Funcion
F1(x:entero;y:carácter):entero
Inicio
Escribir y
Retorno (x+1)
Fin
Funcion
F2(A:entero;B:carácter):entero
Inicio
Escribir “Hola” B
Retorno A
Fin F2
El paso de funciones y
procedimientos como parámetros, nos va a permitir que desde un subprograma
podamos llamar a otros, pero teniendo en cuenta que el subprograma llamado no
va a ser uno determinado, sino que va a depender en cada momento del subprograma
pasado como parámetro real, de esta manera el subprograma puede llamar a un
conjunto de n subprogramas que cumplan unas determinadas características, pero
solo uno en cada momento.
No hay que confundir el paso de
una función como parámetro con la llamada a una función cuando aparece como
parámetro real en la llamada a un subprograma. Para diferenciarlo, cuando paso
una función como parámetro solo pondré su nombre, en cambio cuando llamo a una
función para pasar el valor que devuelve como parámetro pondré el nombre de la
función y con sus argumentos para indicar que ahí se puede hacer la llamada.
Esto se puede hacer porque la llamada a una función puede aparecer en cualquier
expresión en la que apareciese cualquier valor del tipo de datos que devuelve.
Procedimiento P(A:entero)
Inicio
Escribir A
Fin P
Funcion F(x:entero):entero
Inicio
Retorno (x*2)
Fin F
Algoritmo EJ
Var I
Inicio
I 2
P(F(I)) Esto no es pasar una función como
parámetro
Fin

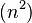 operaciones para ordenar una lista de n elementos.
operaciones para ordenar una lista de n elementos.